我们经常使用malloc或者new等函数或操作符来动态分配内存,这里的内存说的是堆内存,并且需要程序员手工释放分配的内存。malloc对应free,new对应delete。至于你要混着用,也不是不可以,只要确保逻辑和功能的正确性,还要在规范的限制范围内。这里我想插一句题外话,我个人觉得,只要你将一些具有相似特征的东西都摸透了,他们的差异你就会很明了,在此基础上,随便你怎么用都是成竹在胸的,只需要考虑一些外界因素就可以了,比如前面说的规范等。
本文是针对在栈上动态分配内存进行讨论,分配的内存即为栈内存,栈上的内存有一个特点即是不用我们手工去释放申请的内存。栈内存由一个栈指针来开辟和回收,栈内存是从高地址向低地址增长的,增长时,栈指针向低地址方向移动,指针的地址值也就相应的减小;回收时,栈指针向高地址方向移动,地址值也就增加。所以栈内存的开辟和回收都只是指针的加减,由此相对于分配堆内存可以获得一定的性能提升。由这些特性,也能对为什么叫“栈”内存有更进一步的理解。
我们都知道,在C99标准之前,C语言是不支持变长数组的,如果想要动态开辟栈内存以达到变长数组的功能就得依靠alloca函数。其实在gcc下,c99下的变长数组后台也是依靠alloca来动态分配栈内存的,当然这里不能完全说是调用alloca来实现的,alloca可能被优化并内联(当然你还是可以说这是在调用)。这里就不纠结这个问题了,在本文不属于重点。实际中,alloca函数是不推荐使用的,他存在很多不安全的因素,这里暂时不讨论这个问题,本文的目的是了解原理,获得认知,以至通透。
通常编译器都提供了CRT库,例如VC的诸多版本,CRT库在一些版本间差异还是比较大,新版本的CRT一般会多了很多更严格的检查和一些安全机制。本文以VS2008为例,其为alloca提供了对应的_alloca函数,编译器会将其编译为_alloca_probe_16函数,此函数位于VC_dir\VC\crt\src\intel\alloca16.asm汇编源文件中,此乃微软提供的汇编版本CRT相关函数。在此文件中,有两个版本,一个是16字节对齐的_alloca_probe_16,一个是8字节对齐的_alloca_probe_8。代码如下:
view plainprint?
- <p>.xlist
- include cruntime.inc
- .list</p><p>extern _chkstk:near</p><p>; size of a page of memory</p><p> CODESEG</p><p>page</p>public _alloca_probe_8
- _alloca_probe_16 proc ; 16 byte aligned alloca
- push ecx
- lea ecx, [esp] + 8 ; TOS before entering this function
- sub ecx, eax ; New TOS
- and ecx, (16 - 1) ; Distance from 16 bit align (align down)
- add eax, ecx ; Increase allocation size
- sbb ecx, ecx ; ecx = 0xFFFFFFFF if size wrapped around
- or eax, ecx ; cap allocation size on wraparound
- pop ecx ; Restore ecx
- jmp _chkstk
- alloca_8: ; 8 byte aligned alloca
- _alloca_probe_8 = alloca_8
- push ecx
- lea ecx, [esp] + 8 ; TOS before entering this function
- sub ecx, eax ; New TOS
- and ecx, (8 - 1) ; Distance from 8 bit align (align down)
- add eax, ecx ; Increase allocation Size
- sbb ecx, ecx ; ecx = 0xFFFFFFFF if size wrapped around
- or eax, ecx ; cap allocation size on wraparound
- pop ecx ; Restore ecx
- jmp _chkstk
- _alloca_probe_16 endp
- end
默认会编译为16字节对齐的版本,仔细看一下,这里所谓的16字节对齐倒也不一定,lea ecx, [esp] + 8这句获得进入此函数之前的esp值并写入ecx中,这里加8的原因很明显,前4个字节是保存的ecx的值,后4个字节是函数的返回地址,加8即得到上一层函数调用本函数时的esp值,这里没有参数压栈,参数是寄存器传递的。因此,这个ecx的值可以假设为一个定值(这个值也是至少4字节对齐的),然后下面3句汇编代码中,eax是外部传入的要开辟栈内存字节数,这个字节数始终是4字节对齐的。那么sub ecx, eax这句之后的结果就可以是4字节对齐且非16字节对齐,这样一来,在and ecx, ( 16 - 1 )并add eax, ecx后,eax的值就是非16字节对齐的。至于8字节对齐的版本,你可以试着推算一下会不会存在算出的eax是非8字节对齐的,这个不是难点。
在此函数里,我们发现还没有真正的开辟栈内存,因为esp(也就是前面提到的栈指针,也就是栈顶指针,上面的汇编代码中的TOS也就是栈顶:Top of stack的意思)的值还没有减去eax(申请内存的大小)而改变。然后我们注意到,在pop ecx还原ecx的值(因为此函数需要ecx来协助,因此进函数就push ecx保存,然后结束之后再pop 还原)之后,还有一个jmp跳转,跳转到了_chkstk,此函数很明显,意为:check stack,用于检查堆栈是否溢出。此函数通常会被编译器插入到某个开辟了一定大小函数头部,用于进入函数时进行栈内存溢出检查,例如你在一个函数中定义一个较大的数组,此时编译器会强制插入_chkstk函数进行检查(这里单指VC下,其他编译器的方式不一定一致)。
于是,到此可以猜测,这个_alloca_probe_16函数只是负责计算实际对齐后该分配多少字节的栈内存,并保存到eax中,由于_chkstk函数也会用到eax的值,这里也是通过寄存器传参的。并且可以看出_alloca_probe_16函数和_chkstk函数联系紧密,都是直接jmp过去的。
好了,来看看_chkstk函数吧,此函数位于之前的目录下,也是一个汇编源文件:chkstk.asm。代码如下:
view plainprint?
- <p>.xlist
- include cruntime.inc
- .list</p><p>; size of a page of memory</p><p>_PAGESIZE_ equ 1000h</p><p>
- CODESEG</p><p>page</p>public _alloca_probe
- _chkstk proc
- _alloca_probe = _chkstk
- push ecx
- ; Calculate new TOS.
- lea ecx, [esp] + 8 - 4 ; TOS before entering function + size for ret value
- sub ecx, eax ; new TOS
- ; Handle allocation size that results in wraparound.
- ; Wraparound will result in StackOverflow exception.
- sbb eax, eax ; 0 if CF==0, ~0 if CF==1
- not eax ; ~0 if TOS did not wrapped around, 0 otherwise
- and ecx, eax ; set to 0 if wraparound
- mov eax, esp ; current TOS
- and eax, not ( _PAGESIZE_ - 1) ; Round down to current page boundary
- cs10:
- cmp ecx, eax ; Is new TOS
- jb short cs20 ; in probed page?
- mov eax, ecx ; yes.
- pop ecx
- xchg esp, eax ; update esp
- mov eax, dword ptr [eax] ; get return address
- mov dword ptr [esp], eax ; and put it at new TOS
- ret
- ; Find next lower page and probe
- cs20:
- sub eax, _PAGESIZE_ ; decrease by PAGESIZE
- test dword ptr [eax],eax ; probe page.
- jmp short cs10
- _chkstk endp
- end
此函数较之前的要稍微复杂一些,不过代码还是非常清晰易懂的。还是解释一下吧,先来看lea ecx, [esp] + 8 - 4这句,与_alloca_probe_16汇编代码相比较,多了一个减4,这里减4是因为从_alloca_probe_16函数到_chkstk函数之间是用的jmp,而不是call,因此没有返回地址,只有保存的ecx值的4个字节,所以少4个字节的偏移就能取到esp的值了。由于_alloca_probe_16函数是保持栈平衡的,并且没有改变esp的值,因此,_chkstk函数里取到的esp与_alloca_probe_16函数取到的esp是一样的。并且也都存放到了ecx中。后面一句与_alloca_probe_16函数的逻辑一样,都是将ecx(esp的值)减去eax(要分配的栈内存大小,已经由_alloca_probe_16函数对齐过)。这一句之后,ecx的值就是新的esp的值,如果栈没有溢出,那么esp将会被设置为这个新值,于是栈内存分配成功。
继续向下分析,紧接着下面3句,用得有一点巧妙。sbb eax, eax,sbb乃带借位减法指令,如果前面的sub ecx, eax存在借位(ecx小于eax),则sbb之后eax的值为0xffffffff,然后再not eax,eax将变成0,然后再and ecx, eax,则ecx变为0,也就意味着新的esp值为0。这里先放一下,待会儿再向下分析。再看前面,sub ecx, eax存在借位,为什么会存在这样的情况,难道_alloca_probe_16函数不检查申请内存的大小的吗?的确,他并不会关心你想申请多少字节,他只是与_chkstk配合,让_chkstk能够知道申请的内存过大就可以了,过大之后可以由_chkstk进行检查并抛出异常。那么我们来看_alloca_probe_16函数是怎么配合_chkstk函数的检查的呢。这又得回到_alloca_probe_16
函数的汇编源代码中,看这三句:
view plainprint?
- add eax, ecx ; Increase allocation Size
- sbb ecx, ecx ; ecx = 0xFFFFFFFF if size wrapped around
- or eax, ecx ; cap allocation size on wraparound
eax为申请的大小,ecx为新的esp值,由sub ecx, eax计算获得。把这三句代码与_chkstk函数的三句代码结合着看,这里如果eax过大(申请空间过大),add eax, ecx之后,会溢出,即CF位为1。然后执行下一句sbb ecx,ecx,也就等同于:ecx = ecx - ecx - CF = 0 - 1 = -1 = 0xffffffff。然后在or eax, ecx,于是eax为0xffffffff,也就是传给_chkstk函数的申请空间大小。然后再看前面对_chkstk函数的分析,如果eax为0xffffffff,那么肯定会sub溢出,于是ecx(新的esp值)最后为0。再看另外一种情况,如果在_alloca_probe_16中,eax的值大于ecx的值,那么sub之后,会溢出,在and ecx, ( 16 - 1 )之后,再add eax, ecx,此刻假设不会溢出,sbb之后,ecx为0,之后再or eax,ecx不会影响eax的值,但是此时eax还是大于ecx(esp的值)的。当eax传入_chkstk之后,sub会溢出。与eax为0xffffffff的结果一样,都使得ecx(esp的值)的值为0。所以由上面两种情况分析下来,_alloca_probe_16函数和_chkstk函数之间是有一定的配合的。也可以说是_alloca_probe_16函数适应了_chkstk的检查方案。
我们再继续向下分析_chkstk吧,看后面两句,先是mov eax,esp将当前的esp值交给eax,注意这里的esp值是_chkstk内部已经压入保存了ecx原始值之后的esp,这个esp也就是最初有lea ecx, [esp] + 8 - 4获得的上层esp值减4(push ecx占用的4字节)。获得了当前esp值之后,又and eax, not ( _PAGESIZE_ - 1),_PAGESIZE_为0x1000,也就是4096字节(4KB),即为windows页内存大小规则之一。这句代码也就是将当前esp所在的页剩下的字节全部减掉,到达这一页的末尾下一页的开始。这样做是方便后面的栈溢出检查。
之后,有两个标签cs10和cs20,cs10的开头是判断ecx是否小于eax,此刻的eax已经是某页的开头,如果ecx小于这个eax所存的地址值,则跳转到cs20标签里,cs20标签里代码很简单,进入就将eax减掉一页内存,然后是test dword ptr [eax],eax这句,这句存在一个内存访问,可以想象如果eax所存的内存值不可读,那么就会抛出异常。这里正是利用这一点,当这里不异常,又会跳转到cs10标签里继续比较,如果还是小,则在减一页,再进行访问,直到ecx大于等于eax或者抛出异常。那么再想一下上面分析的逻辑,如果申请的空间过大,ecx的值会为0,那么在cs20中判断,0会一直小于eax,这样eax会一直减4K,直到eax为0,这里显然减不到0就已经抛异常了。当eax减到一定时候,则会在test dword ptr [eax],eax这句抛出一个栈溢出的异常,如下图:
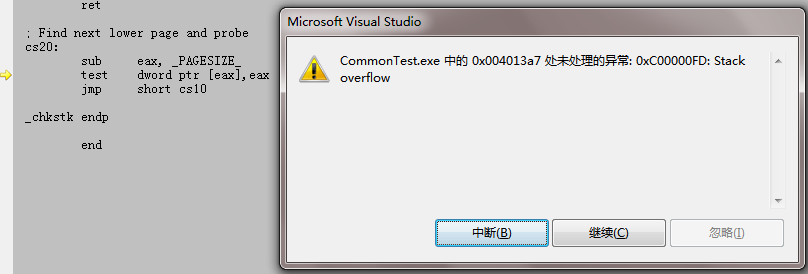
如果继续执行,则会发生访问异常。如果申请的大小不会导致栈溢出,则当eax减到一定时候ecx大于等于eax,或者第一次进去时ecx就是大于等于eax的,则进入正常开辟空间的逻辑:
view plainprint?
- mov eax, ecx ; yes.
- pop ecx
- xchg esp, eax ; update esp
- mov eax, dword ptr [eax] ; get return address
- mov dword ptr [esp], eax ; and put it at new TOS
- ret
第一行是将ecx(新的通过验证的esp)赋值给eax,然后是还原ecx的值,第三行就是将当前的esp值和eax做交换。esp便是开辟空间后的新值,此刻肯定比eax的值要小(栈向低地址延伸)。然后是第4句,此时eax是pop ecx之后的esp值,也就是call _alloca_probe_16函数压入了返回地址后的esp值,因此,第四句执行后,eax的值就是,_alloca_probe_16函数函数的返回地址,我们准备返回到上层,这里的上层不是_alloca_probe_16函数,因为他们之间不是call的,而是jmp的,不存在返回地址压入。这里的上层是_alloca_probe_16函数的上层。第5行,是将eax存入当前的esp指向的内存中,因为下一条指令ret,即将读取这个地址,并返回到上层,其间的原理请参考《Inline Hook 之(监视任意函数)》,此文有相同的用法。
整个过程就是这样了,其实在很多C语言编写的实际项目中,还是有用到alloca。就我个人而言,我觉得不管他有什么优点和缺点,只要弄清楚了他的这些特性,完全可以规避他的缺点,而发挥他的优势。而且也确实动态分配适量的栈空间,能获得一些性能。本文只是为了介绍其原理和细节,不在此争论辩证性的论题。
如果要使用alloca,可以非常简单的使用,如下:
view plainprint?
- void func( void )
- {
- int* p = ( int* )alloca( 4 );
- *p = 100;
- }
不用自己管理释放,当函数结束时,esp会平衡。另外,需要提到的是,根据alloca申请的大小的变化,编译器可能在后台做一些调整,比如当申请的内存较小时,alloca直接被编译成_chkstk,而不会调用_alloca_probe_16函数,这也算是一个小小的优化吧。再比如,在VS2003下,不管申请多大的空间,都会将alloca直接编译成_chkstk。因为vs2003的CRT没有提供_alloca_probe_16函数的实现。
上面提到的alloca,在VC的CRT中其实是一个宏定义,#define alloca _alloca。另外还有一些CRT宏定义,例如_malloca,这个宏定义也等于是一层封装,在debug下,_malloca调用的是malloc,在release下,当申请的大小小于一定值时,调用的是alloca,否则调用malloc。因此,需要调用_freea来释放内存,_freea会根据标记,判断是malloc分配的还是alloca分配的,如果是malloc分配的堆内存则调用free,如果是alloca分配的栈内存,则不用释放。代码如下:
view plainprint?
- // _malloca的定义
- #if defined(_DEBUG)
- #if !defined(_CRTDBG_MAP_ALLOC)
- #undef _malloca
- #define _malloca(size) \
- __pragma(warning(suppress: 6255)) \
- _MarkAllocaS(malloc((size) + _ALLOCA_S_MARKER_SIZE), _ALLOCA_S_HEAP_MARKER)
- #endif
- #else
- #undef _malloca
- #define _malloca(size) \
- __pragma(warning(suppress: 6255)) \
- ((((size) + _ALLOCA_S_MARKER_SIZE) <= _ALLOCA_S_THRESHOLD) ? \
- _MarkAllocaS(_alloca((size) + _ALLOCA_S_MARKER_SIZE), _ALLOCA_S_STACK_MARKER) : \
- _MarkAllocaS(malloc((size) + _ALLOCA_S_MARKER_SIZE), _ALLOCA_S_HEAP_MARKER))
- #endif
- // _freea的定义
- _CRTNOALIAS __inline void __CRTDECL _freea(_Inout_opt_ void * _Memory)
- {
- unsigned int _Marker;
- if (_Memory)
- {
- _Memory = (char*)_Memory - _ALLOCA_S_MARKER_SIZE;
- _Marker = *(unsigned int *)_Memory;
- if (_Marker == _ALLOCA_S_HEAP_MARKER) // 判断是否是堆标记
- {
- free(_Memory);
- }
- #if defined(_ASSERTE)
- else
if (_Marker != _ALLOCA_S_STACK_MARKER) - {
- _ASSERTE(("Corrupted pointer passed to _freea", 0));
- }
- #endif
- }
- }
- // _MarkAllocaS的定义
- __inline void *_MarkAllocaS(_Out_opt_ __crt_typefix(unsigned int*) void *_Ptr, unsigned int _Marker)
- {
- if (_Ptr)
- {
- *((unsigned int*)_Ptr) = _Marker; // 打上标记, _ALLOCA_S_STACK_MARKER 或 _ALLOCA_S_HEAP_MARKER
- _Ptr = (char*)_Ptr + _ALLOCA_S_MARKER_SIZE;
- }
- return _Ptr;
- }
【延伸】
这里延伸一个玩儿的用法,就是在写C语言程序时,有多个函数参数是指针并且参数个数一样,这些函数的指针参数的类型都不一样,在C++里有template,在C里可没有。于是为了实现一个类似功能的东西,我们就可以用alloca来申请参数的空间,然后调用函数。代码如下:
view plainprint?
- #include <stdio.h>
- #include <malloc.h>
- void func( char* p )
- {
- printf( "%s\n", p );
- }
- void chk( void* arg )
- {
- if ( ( void** )arg - &arg != 1 ) // 检查参数的位置是否紧挨着arg所在的内存地址
- __asm int 3 // 如果紧挨着,当chk执行完之后,esp即刚好指
- } // alloca申请的空间,因此,调用fun时就有参数了
- typedef
void ( *functor )( void );
- int main( void )
- {
- char* str = "12345";
- int* arg = ( int* )alloca( 4 );
- functor fun = ( functor )func;
- *arg = ( int )str;
- chk( arg );
- ( *fun )();
- return 0;
- }
这里只是一个简单的例子,由于alloca申请的空间最后在函数结束时会平衡栈帧便回收了,而fun指针的调用是没有压入参数的,因此fun结束后不存在add esp,func函数是__cdecl调用约定,也不会在内部平衡栈,所以整个栈帧是平衡的。
PS:此例子纯属玩乐,了解其中原理而已,更复杂的情况,并没有测试和深入。
不知不觉已经凌晨3点半了,本文对于了解原理并熟悉汇编的朋友可能罗嗦了,可以直接略过分析,我该睡觉了!欢迎交流!
****************如需转载,请注明出处:http://blog.csdn.net/masefee,谢谢**********************

 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2011-12-6 11:53:52
发表于 2011-12-6 11:53:52
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡